
I had a great time as a guest on David Sparks and Katie Floyd’s milestone MacPowerUser Show 100 yesterday. Their podcast has been a staple on my iPod and iPhone for years. To celebrate they invited 10 guests to discuss workflows in their professional lives. Over the past several years, I have learned an incredible amount from Katie and David. It was nice to be able to give something back.I had the pleasure of discussing a portion of my writing workflow–how I get information into my academic research library-Papers2. I’ve talked about why I use Papers in a previous entry. If you’re not familiar with Papers you should read my previous post first. Go ahead. I’ll wait.——————————- Okay, welcome back.When tackling a new writing project I pass through several stages:
- collecting
- organizing
- reading
- synthesizing
- citing
The workflow I covered on the MacPowerUsers had to do with collecting information. I usually obtain scientific literature in one of three ways:
- as a recipient of an Endnote library (when writing collaboratively)
- through personal searches on the web
- as an attachment to a colleague’s email.
I’ll cover each of these contingencies below.Endnote still has quite a foothold in academics. I often find my collaborators have not yet made the switch to Papers. Many times, when writing collaboratively, we must share libraries between the two applications (Endnote and Papers). Fortunately Papers can import (and export) Endnote libraries seamlessly (as long as they’re in Endnote XML format). Easy and no need for a workflow!However, the other two situations are more complex (searching myself or receiving attachments to emails) and require a workflow–making use of the wonderful program called Hazel. Hazel monitors folders on my computer and acts on individual files according to rules I create. Hazel can even peek at the content of files and “recognize” what's inside. I have Hazel monitoring about a dozen folders on my Mac, but my Downloads Folder keeps Hazel the busiest. I have about two dozen rules running on my Downloads Folder alone.For this particular writing workflow I ask Hazel to look at the contents of every PDF in my Downloads Folder and match files that have words unique to scholarly publications. I’ve found having Hazel search for the word “References” within each PDF works the best. When a PDF whose contents contain the word “References” is matched, Hazel automatically launches Papers and imports the manuscript. While importing, Papers fetches metadata, renames the PDF to the convention I’ve specified, and files the manuscript in a specified hierarchy on DropBox–all automatically. Another preference in Papers erases the original file once it’s imported.
I’ve found having Hazel search for the word “References” within each PDF works the best. When a PDF whose contents contain the word “References” is matched, Hazel automatically launches Papers and imports the manuscript. While importing, Papers fetches metadata, renames the PDF to the convention I’ve specified, and files the manuscript in a specified hierarchy on DropBox–all automatically. Another preference in Papers erases the original file once it’s imported.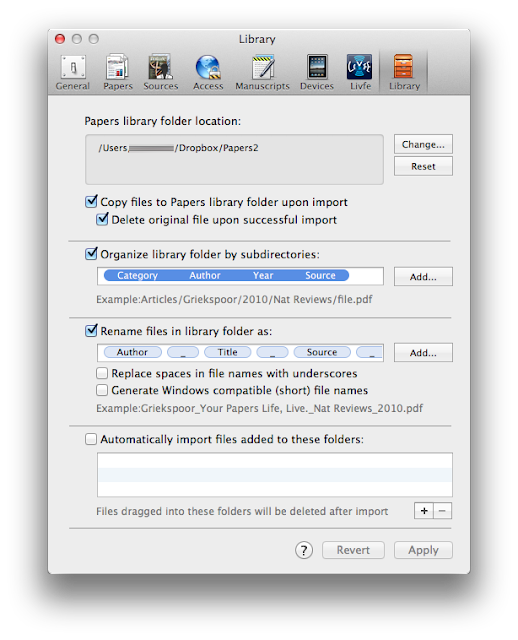 I’ve tried other search words for Hazel including “abstract,” “methods,” “results,” and “discussion”–none work as well as references. Most every scholarly manuscripts has references (unfortunately, even the word “references” will not be 100% reliable–in a minority of publications, references will be called a "bibliographies" or "citations").You are probably wondering why I don’t just use the built in unified search window in Papers. My answer: it is faster and less frustrating to find full-text directly through our Library’s web page. Papers unified search will work through a fire wall (using proxy URLs in the search interface) – but it’s hit-or-miss whether a link in Papers will lead to a full-text article or merely a frustrating publisher’s login screen–most usually the latter. My hit rate is much higher on the web. I use Papers built-in search engine primarily to retrieve metadata (after the full text pdf has already been imported).When I’m collecting full-text articles I save EVERYTHING to my Downloads Folder and let Hazel do the rest. When she finds a match, she launches Papers and imports each manuscript without any additional effort on my part. Using this method, I can conduct my search for scholarly information with minimal interruptions - Hazel does the rest.Searching on my own is the most common way I get information into papers, but occasionally a colleague will mail me something they think I should read. For these situations here’s what I do. I have Hazel monitor my Mail Downloads folder (~/Library/Containers/com.apple.mail/Data/Library/Mail Downloads ) and copy EVERY attachment to my Downloads Folder (I do this for a host of reasons–not just publications–I’ll talk about why in a future entry) Once the paper is in the Downloads folder Hazel can work her magic using the rule mentioned earlier. Apple now hides the Library Folder by default. Here is a quick tutorial on how to find it on your hard drive (works for Lion or Mountain Lion).
I’ve tried other search words for Hazel including “abstract,” “methods,” “results,” and “discussion”–none work as well as references. Most every scholarly manuscripts has references (unfortunately, even the word “references” will not be 100% reliable–in a minority of publications, references will be called a "bibliographies" or "citations").You are probably wondering why I don’t just use the built in unified search window in Papers. My answer: it is faster and less frustrating to find full-text directly through our Library’s web page. Papers unified search will work through a fire wall (using proxy URLs in the search interface) – but it’s hit-or-miss whether a link in Papers will lead to a full-text article or merely a frustrating publisher’s login screen–most usually the latter. My hit rate is much higher on the web. I use Papers built-in search engine primarily to retrieve metadata (after the full text pdf has already been imported).When I’m collecting full-text articles I save EVERYTHING to my Downloads Folder and let Hazel do the rest. When she finds a match, she launches Papers and imports each manuscript without any additional effort on my part. Using this method, I can conduct my search for scholarly information with minimal interruptions - Hazel does the rest.Searching on my own is the most common way I get information into papers, but occasionally a colleague will mail me something they think I should read. For these situations here’s what I do. I have Hazel monitor my Mail Downloads folder (~/Library/Containers/com.apple.mail/Data/Library/Mail Downloads ) and copy EVERY attachment to my Downloads Folder (I do this for a host of reasons–not just publications–I’ll talk about why in a future entry) Once the paper is in the Downloads folder Hazel can work her magic using the rule mentioned earlier. Apple now hides the Library Folder by default. Here is a quick tutorial on how to find it on your hard drive (works for Lion or Mountain Lion). So there it is: how I use Hazel to speed up the collection of information when writing or researching. I hope it’s helpful to you. In a future entry I’ll talk about an emerging trend in research paper management: social networking.Cheers, Jeff
So there it is: how I use Hazel to speed up the collection of information when writing or researching. I hope it’s helpful to you. In a future entry I’ll talk about an emerging trend in research paper management: social networking.Cheers, Jeff