

One of the most popular entries on WIPPP has been my 2015 Writing Workflow. My workflow has changed substantially over the last several years. I thought I'd share what I'm currently doing.
Read moreModification to Reading, Extracting And Storing Scholarly Information To Supercharge The Writing Process
In Reading, Extracting And Storing Scholarly Information To Supercharge The Writing Process, I wrote about how I extracted both highlights and full-text of entire manuscripts in order to give me granular access to information. Although I’ve continued my extraction of highlights, the extraction of full text (by highlighting the entire document) proved much too time consuming. Instead, I’ve been experimenting with an alternative that is much quicker (as suggested by Andrew in the comments of the entry)—saving the entire manuscript as single-page PDF documents. Here is what I’ve been doing.
After highlighting a manuscript in Highlights.app, I extract my highlights (along with color tags) to Devonthink Pro using the built in export function. By default, Highlights.app saves my extracted highlights files to the DTP Inbox. I move the folder from the DTP Inbox to my Desktop. Within the moved folder I make two new sub-folders: 1. HighlightsX and 2. PDFx. I then move the extracted markdown files to the HighlightsX sub-folder.Within Bookends, I export the annotated pdf to my desktop. There, I open the file with Adobe Acrobat (any app able to add headers and split documents will work).
Read moreAutomating the Organization and Accessibility of Academic Literature: Bookends and Devonthink Pro
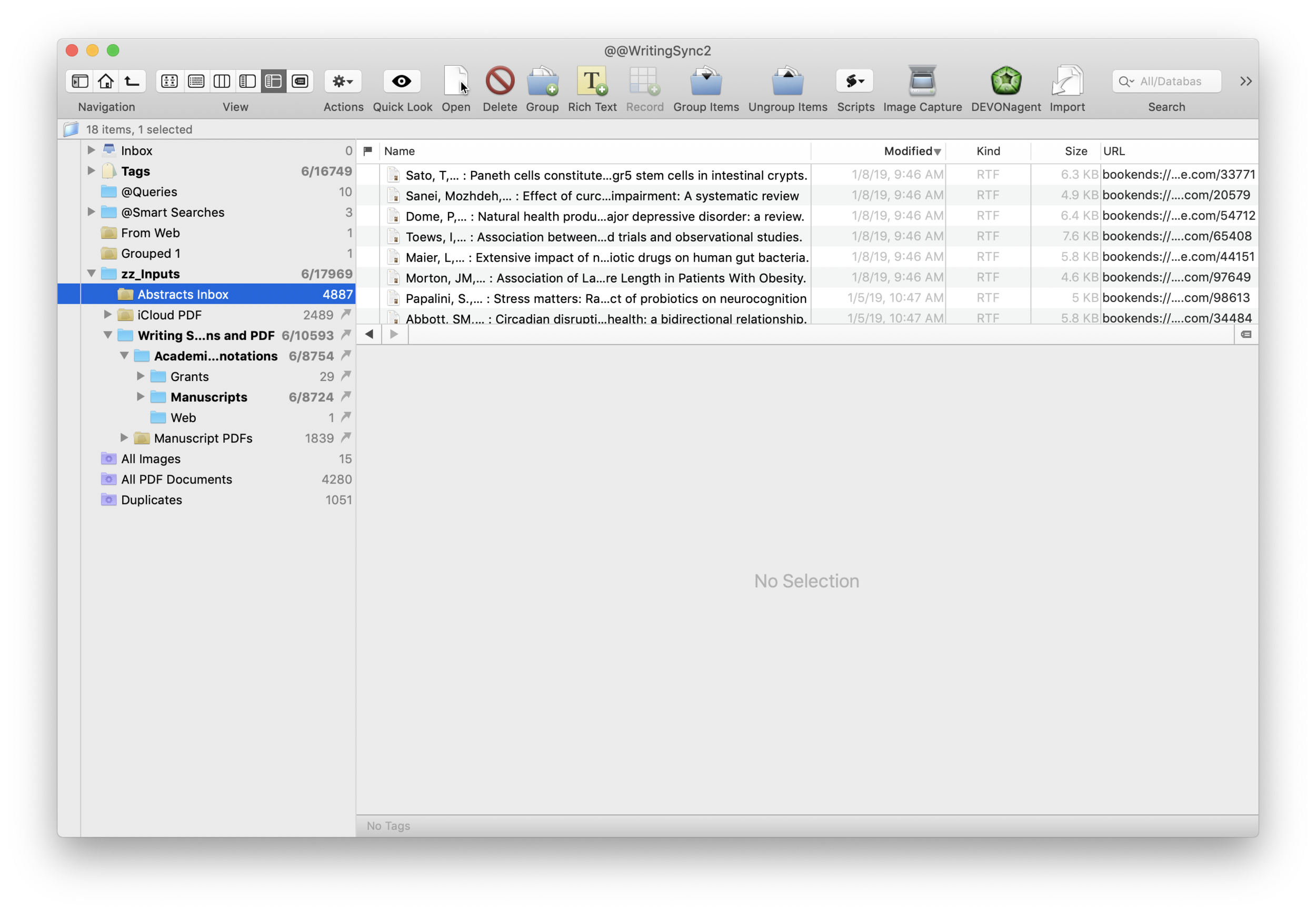
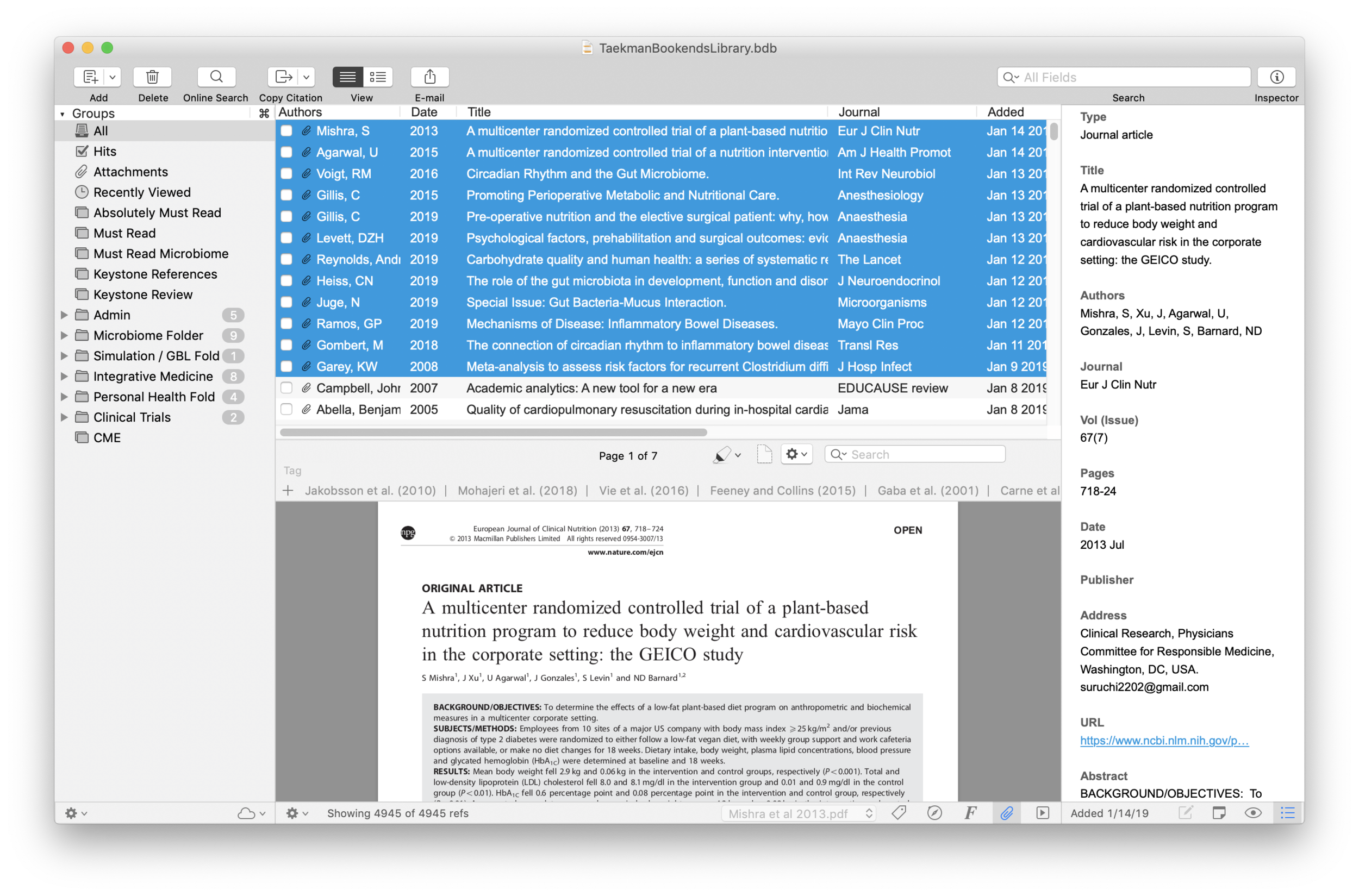
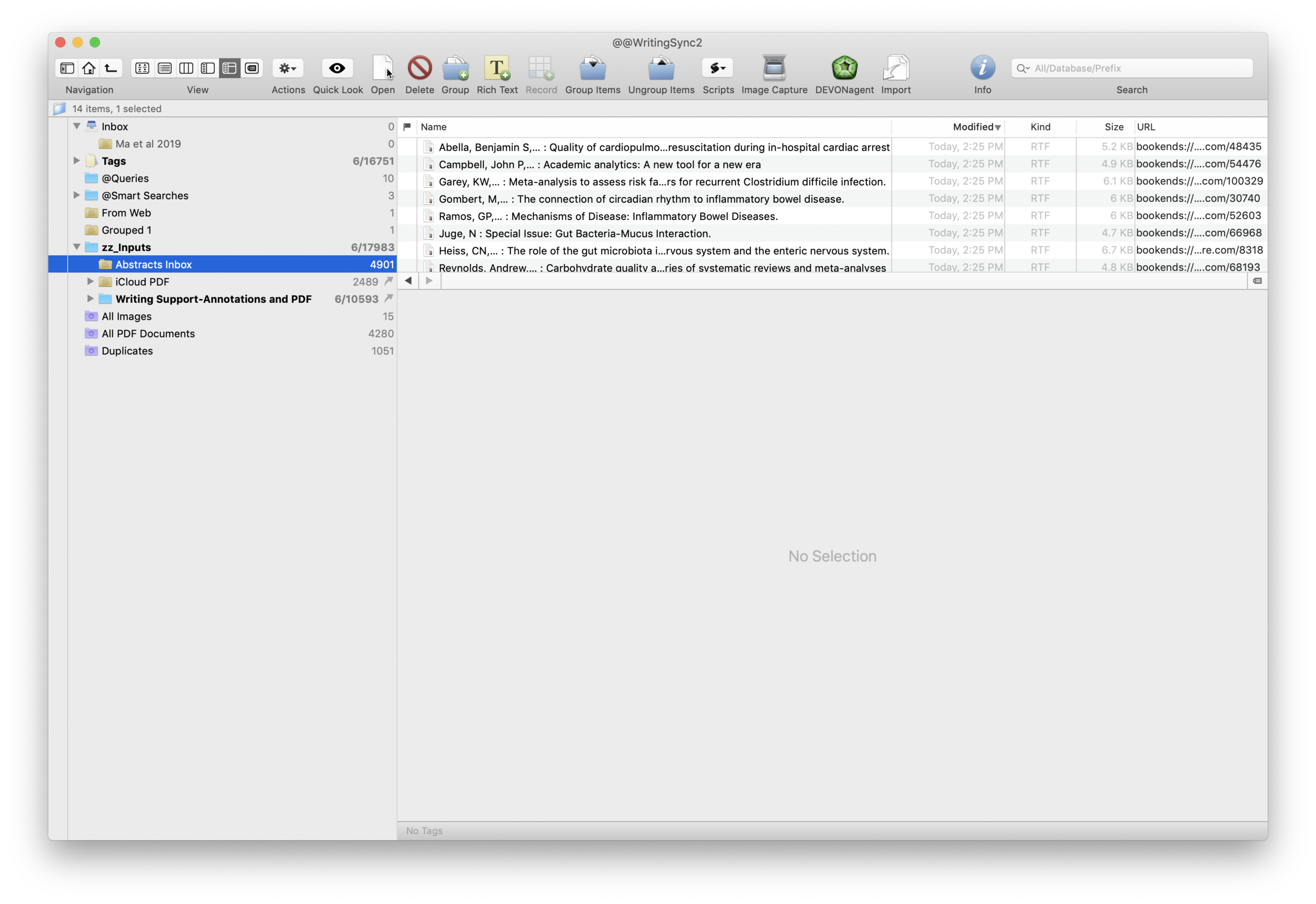

I wrote about Sense-making of the Academic Literature back when I was using Papers. My old workflow required Keyboard Maestro to extract abstract information to Tinderbox. Although Tinderbox is great for visually organizing your notes, it can’t compare to the search capabilities of DevonThink Pro.Since switching to Bookends, I’ve found myself spending less time in Tinderbox and even more time in Devonthink. I’ve made heavy use of a particular built-in Devonthink Template that automates the migration of abstracts from Bookends to DTP (with a link back to Bookends). Once imported into DTP, these abstracts can be parsed using smart folders (enduring searches) that make your literature library a dynamic resource for writing.I have a single DTP database that has indexed the various folders critical in my writing process (e.g. PDFs, extracted notes). In DTP, I’ve organized these folders into a “zz-Inputs Folder”. As you can see below, a sub-folders of zz-Inputs is an “Abstracts Inbox.” When I set up this folder in DTP, I made sure the folder WAS NOT excluded from tagging (this is done by option-clicking on the folder and making sure “exclude from tagging is UNCHECKED).When it’s time to transfer abstracts from Bookends, I first click to select the Abstracts Inbox folder in DTP.I then open up Bookends and sort the fields by the “Added” Column. I like reverse chronological order so I can see the last date I imported abstracts. I highlight all the new manuscripts in Bookends.I then move over to DTP and select the Data:New From Template: Education: Reference (from Bookends) menu item. DTP grabs all the highlighted abstracts from Bookends.The imported information includes Author, Title, Year, Abstract, and Keywords. The template also includes a link back to the publication in Bookends. Finally, there is a field for me to add my own comments to the new DTP file.Once the abstracts are imported into DTP, I make sure to index the folder so the new information is included in search. Now that the information is in DTP I am able to take full advantage of its search functionality and artificial intelligence.I make extensive use of Smart Searches in DTP. Using Smart Searches, The abstracts are automatically sorted into folders.For most topics I have two Smart Searches:
as shown below that includes the search criteria AND searching for the tag “Abstracts Inbox” we talked about earlier—this finds only abstracts relevant to the search,
only the search criteria—this returns ALL information in the database (including abstracts, PDFs, and extracted text as described in this entry).



In DTP, I bring up the Search Interface (Tools: Search….) and type in my search criteria. By default, in the Search Interface, DTP will search across all databases. Notice on the left hand side I have limited the search to my Writing Database. This returns ALL matching information ONLY in my Writing Database. I’ve color coded information extracted from articles using Highlights (for instance, a blue highlight is a direct quote). I can further limit the search by clicking on the “Advanced…” Button and adding additional criteria (e.g. tags, file types, words such as “blue,” etc.).Once I’ve found an abstract that interests me, I locate semantically similar information by highlighting the abstract in DTP and then clicking on the “See Also” button (the Magic Hat).Using this method, all the information I’ve collected (both read and unread) is easily accessible. I use this method extensively when writing. Please let me know if you find it useful too.
Bookends Adds Floating Citation Window
I’d like to bring the latest update of BookEnds to your attention.This update fixed an error that would crash the Bookends when trying to obtain a reference (or link back to a reference in Bookends using a DOI link) from Highlights.app. The latest update fixes this error. Clicking on the reference link in Highlights now selects the reference in Bookends without having to modify the Highlights markdown file. This obviates the need to modify the Highlights markdown file as mentioned in this entry.The latest update also added a floating citation window to Bookends. Like Papers, the floating citation window is invoked using customizable key combinations. So far, I’ve cited using the floating window in Scrivener, Ulysses, and Highlights.app. It works flawlessly.Well done Jon and Sonny Software!
Papers 3 now supports Scrivener 3!
I had a pleasant surprise today. I opened up Papers to find an update. The update includes support of Magic Citations in Scrivener 3. Thank you ReadCube!
Mourning the loss of Integration Between Papers and Scrivener
Early indications, including personal communication with ReadCube personnel, are that Magic Citations (now called SmartCite) will no longer integrate with Scrivener. The new Papers app will only work with Microsoft Word. Bibliography formatting is not an issue for me. The biggest loss is the ability to add citations on the fly in Scrivener without interupting my writing flow.The news of this impending feature loss (along with the announcement of an annual fee) had me scrambling to invesitgate my options for citation managers. During my search, I came across this Wikipedia article, Comparison of Reference Management Software with a great table that collates the majority of software out there.My needs are the following:
- Ability to organize and search through metadata and pdfs
- Integrated citation insertion with Scrivener and Ulysses
- Ability to insert citations while writing on an iOS device
- Ability to annotate PDFs and export each comment individually appended with the article's metadata
- Ability to export metadata (to enable my workflows for sense-making and export of annotations)
I looked at the following:
No product currently fills the void left by Papers, although the consensus of users (both those seeking alternatives to Papers and those who are being forced to leave Sente) seems to be to move to Bookends. I tried the demo version of Bookends and was not impressed. I am waiting impatiently for the release of ReadCube Papers. If the majority of features are retained, I will likely bite the bullet and pay the annual fee. I plan to figure out a work-around to add citations to Scrivener / Ulysses.I'd be interested in hearing your plans / thoughts on academic citation managers.
ReadCube Release of Papers App
If you’ve read my blog, you know I’m invested in Papers. The majority of my writing workflows use the app.I’ve been following news about the app with trepidation. Papers “teamed up” with RedCube in March of 2016. Readcube / Papers have been working on a new version of the app. Although the screenshots look reminiscent of Papers, there will be at least one major change; Papers is moving to a subscription model. I have not found pricing information yet.The combination of a new version, and unknown pricing model, and a distrust of traditional publishers has left me wanting to explore my options.I’m curious what app each of you is currently using for manuscript management and bibliography generation (and why). Please leave comments below.Addendum: Beware. Updating to Scrivener 3 breaks Magic Citations in Papers. From what I've read online, Readcube is not saying when (or if) this issue will be resolved.
Highlights.app Redux
I was too quick to judge the program Highlights. I gave Highlights a second chance, and although not perfect, the app is slowly winning me over. Highlights has greatly sped up the extraction of information from my reading.First a little background. I use Papers for my PDF and bibliographic management. I’ve written about how I extract highlights and annotations into individual files along with their relevant references. The reason to go to this trouble is to enable Devonthink’s artificial intelligence. The Devonthink AI uses word count to find related information in other files. I use this method extensively in my writing of grants and manuscripts. With my previous method, I found by adding references to each annotation (thus similar words) I was interfering with Devonthink’s ability to find relevant information. In order to improve Devonthink’s accuracy, I stopped adding references to each individual annotation. Instead, I merely include a Papers Link back to the original file.Highlights shows the annotations you make in the app's right-hand column. A pop-up interface within Highlights allows you to make comments, underline , change colors, etc. The killer feature of Highlights is single-command extraction of each annotation / comment to its own file. This feature allows me to extract highlights (and metadata) without having to invoke my Keyboard Maestro macros. When the data is extracted into Devonthink, the individual files are in Markdown. This makes the extracted information easy to view and edit.Although I’m more enthusiastic about Highlights, there are several quirks you should understand:
When Highlights explodes your annotations into individual files, it prepends the original file’s name. If you use Highlights from within Papers (e.g. selecting Highlights as your PDF reader of choice from within Papers) you will end up with a ridiculous, machine based title in your metadata. This is not Highlights fault. The use of non-intuitive file names is one of my pet peeves about Papers. The workaround is to export a copy of the PDF to your Desktop and then launch the exported file using Highlights. Using this method, the author’s name and the title of the manuscript along with the year of publication are all prepended to each markdown file.
After reading and highlighting, I edit the markdown headers in Highlights (choosing the edit tab in the annotations window). I erase all but the primary author’s name and then add the Paper’s Citation and a Papers Link back to original file (copied from Paper’s Edit Menu). There is another quirk here. In Highlights Edit Mode, if you don’t leave a space between the markdown coding and the information you add, your file will be reset back to its original state, erasing your modifications.
Highlights has the ability to automatically look up DOI numbers. When it works, it’s great. It takes a single click to import a reference from the bibliography into your Paper’s Database. Unfortunately, this feature is flaky, especially with longer manuscripts. I often have to revert to my Launchbar scripts to capture the bibliographic information I need.
Once I’ve added the metadata I want to the master annotation file (and collected the references of interest), from within Highlights, I choose Export >> Devonthink. Highlights creates individual markdown files for each of the annotations. Each individual file contains the master file’s metadata. The data is copied to my Devonthink Global Inbox. I move the folder from the Devonthink Inbox to my Desktop and from there to my Annotations Folder using Launchbar.Highlights has significantly sped up the time it takes to process a manuscript. Using this method, I’m also having greater success with the “See Also” feature of Devonthink. I hope it works for you too.
Sense-making of Academic Literature using Tinderbox
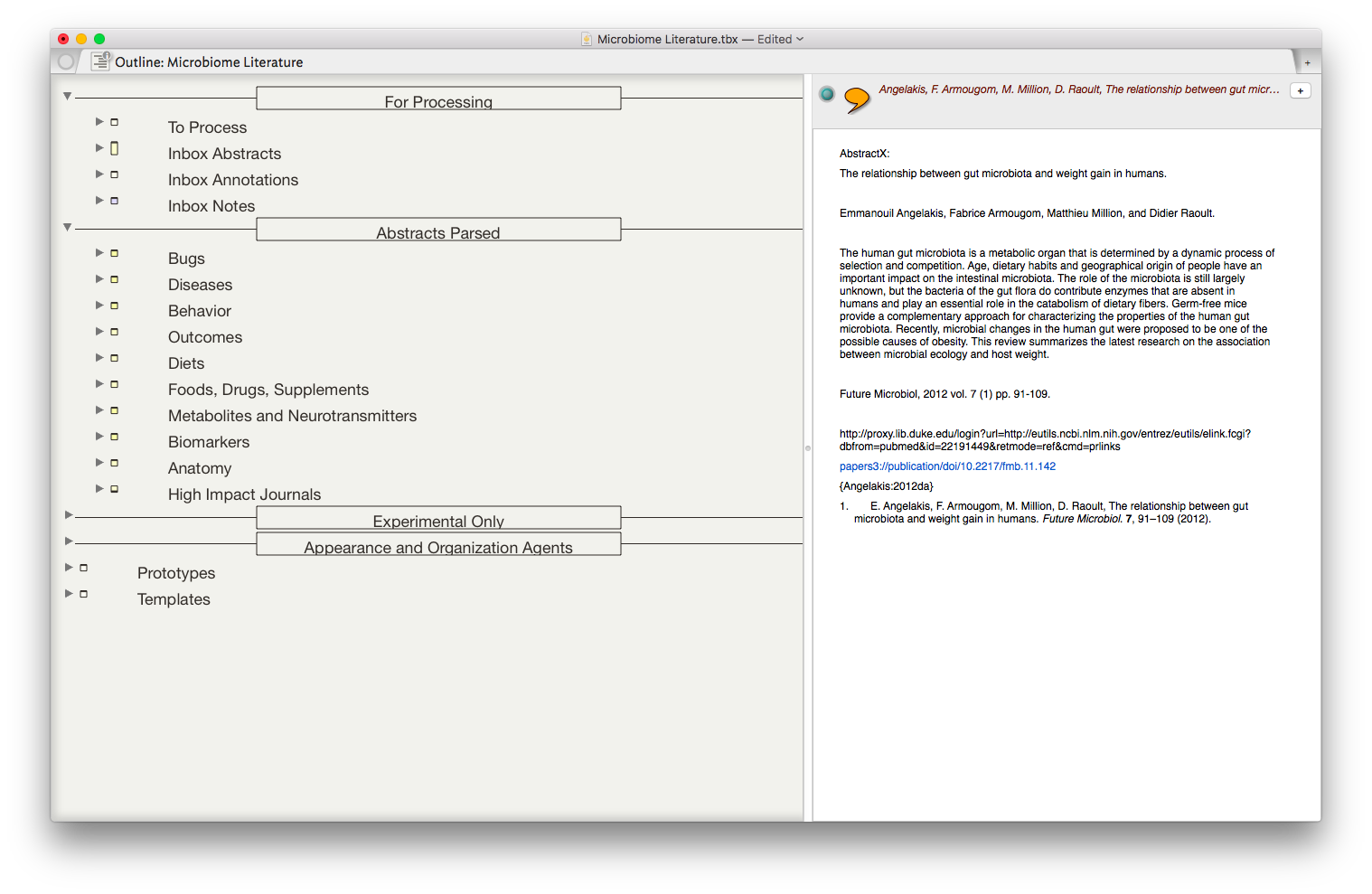
I began using a program called Tinderbox many years ago. Although I understood the program was very powerful, I never took the time to dig into its many features. Over the last six months I've been incorporating Tinderbox into my Writing and have been extremely impressed at the depth of features and the incredible capabilities it adds to my workflow.Don’t feel badly if you haven’t heard of Tinderbox—It's a bit hard to explain. One might call it a hypertext personal information management tool—but that description really doesn’t do it justice. If you’re interested and would like to orient yourself to what Tinderbox is, try this Macworld review of Tinderbox 5 (the current version is 7).An increasing amount of my time is now spent thinking about the rapidly evolving information on the human microbiome. I have read hundreds of papers in this domain, but, like most academicians, I struggle to keep track of the things I’ve Taken in, and how it connects to past and future information. I decided microbiome information was the perfect use case for Tinderbox and finally bit the bullet. To say I've been impressed would be an understatement.The first step was getting the abstracts and metadata from Papers into Tinderbox. I used Keyboard Maestro to build a script to automate the process. The script uses TextEdit to build a document that includes the title, authors, abstract, Pubmed link, Papers link, and Papers citation.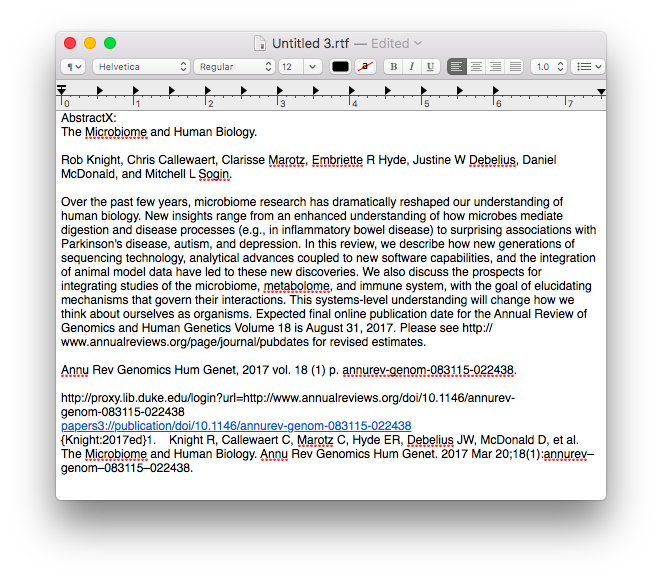 Once the information is assembled in Textedit, the whole note is copied to Tinderbox.
Once the information is assembled in Textedit, the whole note is copied to Tinderbox.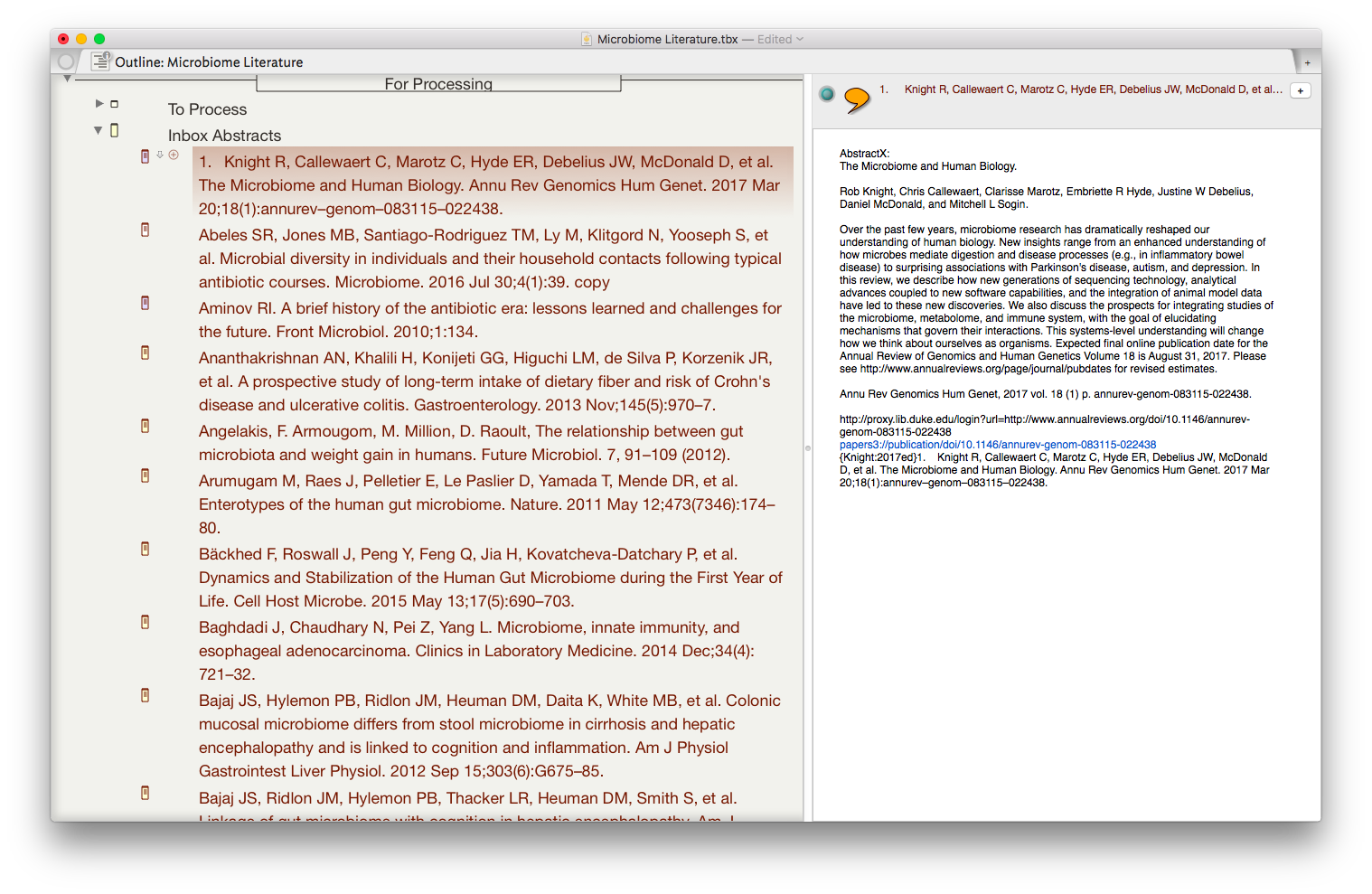 I then put together an assortment of agents that search across the entirety of the imported information and aggregate information similar information under a single heading.
I then put together an assortment of agents that search across the entirety of the imported information and aggregate information similar information under a single heading.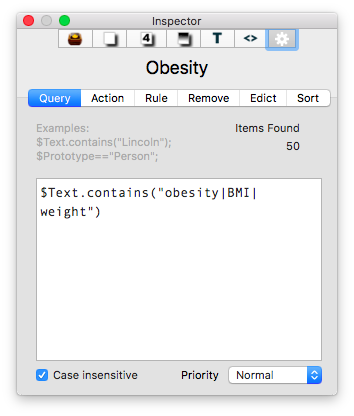
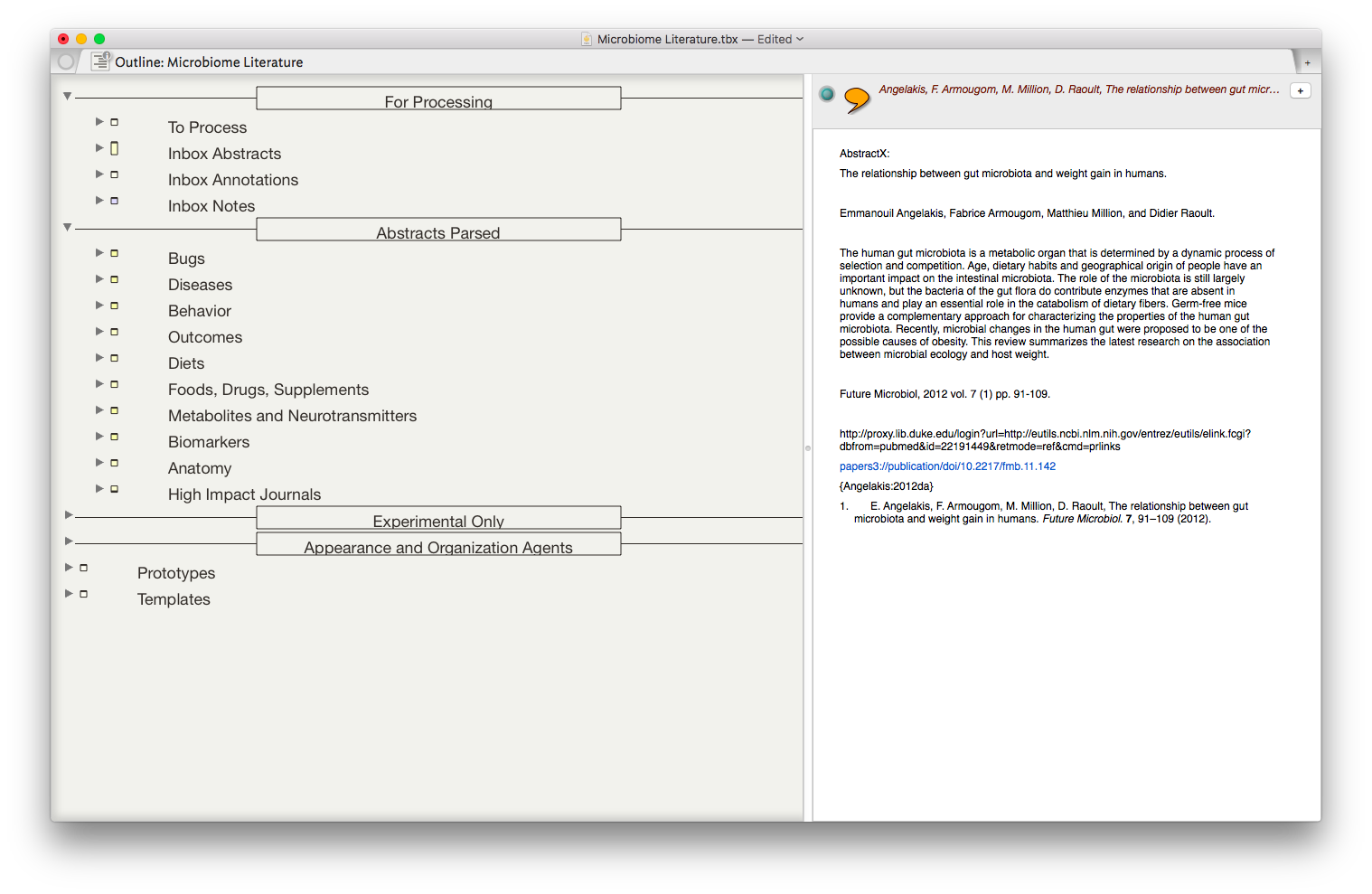 The result is the ability to rapidly find related Information, in an organized fashion, on virtually any topic I’ve read. As I digest new information, I add the abstract and metadata to my Tinderbox Inbox and the agents do the rest—duplicating the abstract into the relevent topics throughout my outline.
The result is the ability to rapidly find related Information, in an organized fashion, on virtually any topic I’ve read. As I digest new information, I add the abstract and metadata to my Tinderbox Inbox and the agents do the rest—duplicating the abstract into the relevent topics throughout my outline.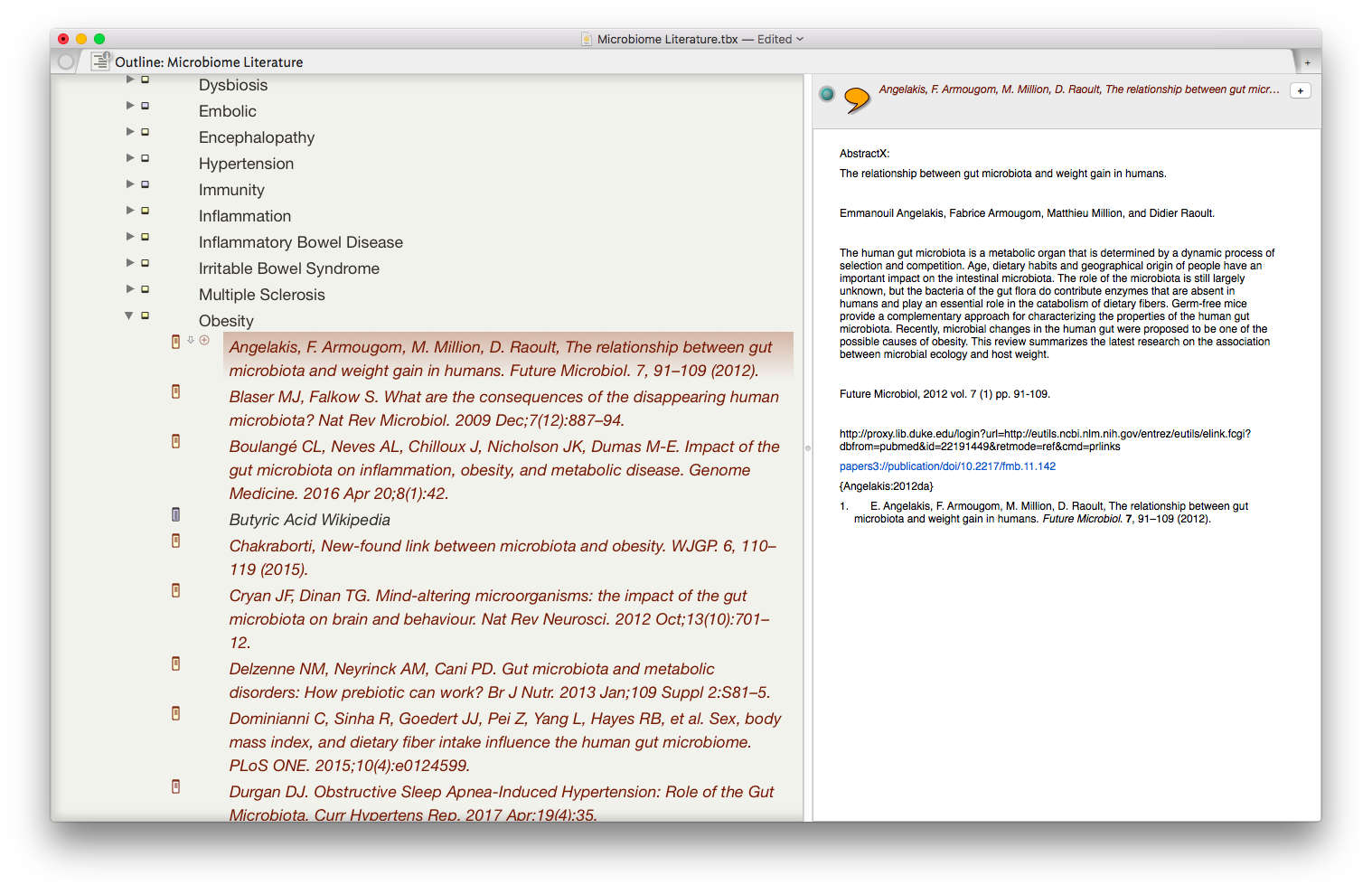 I have been using the collection of abstracts as the starting place for writing manuscripts and grants. Tinderbox can export Individual items, or the entire document outline as OPML—making it easy to import into OmniOutliner, or more commonly for me, Scrivener. I’ve found myself starting with Tinderbox, then making queries in Devonthink as the idea evolves.Although it has taken a significant amount of time inputting the abstracts into Tinderbox, I am already reaping rewards. It worked so well with the microbiome, I’m using the same method (and scripts) with each of the major areas of my academic life: simulation, integrative medicine, and the microbiome.Tinderbox has an incredible feature set, but it has a very steep learning curve. That is where the User Forums come in. There is an active and friendly group of Tinderbox experts more than willing to answer even the most basic question. I have found digging through both the new and old forums incredibly useful while learning to use this incredible piece of software.Although I spend the majority of my time in the outline mode, Tinderbox offers the opportunity to visualize information in a variety of different ways including basic maps, tree maps, and a whole host of other methods. These options add many other possibilities,. There are hundreds of features I have not covered in this entry but will in future entries. The program is so feature-rich, I've only begun to wrap my mind around the many ways Tinderbox can be used.A few caveats with my Keyboard Maestro script:
I have been using the collection of abstracts as the starting place for writing manuscripts and grants. Tinderbox can export Individual items, or the entire document outline as OPML—making it easy to import into OmniOutliner, or more commonly for me, Scrivener. I’ve found myself starting with Tinderbox, then making queries in Devonthink as the idea evolves.Although it has taken a significant amount of time inputting the abstracts into Tinderbox, I am already reaping rewards. It worked so well with the microbiome, I’m using the same method (and scripts) with each of the major areas of my academic life: simulation, integrative medicine, and the microbiome.Tinderbox has an incredible feature set, but it has a very steep learning curve. That is where the User Forums come in. There is an active and friendly group of Tinderbox experts more than willing to answer even the most basic question. I have found digging through both the new and old forums incredibly useful while learning to use this incredible piece of software.Although I spend the majority of my time in the outline mode, Tinderbox offers the opportunity to visualize information in a variety of different ways including basic maps, tree maps, and a whole host of other methods. These options add many other possibilities,. There are hundreds of features I have not covered in this entry but will in future entries. The program is so feature-rich, I've only begun to wrap my mind around the many ways Tinderbox can be used.A few caveats with my Keyboard Maestro script:
- The item you wish to extract must be highlighted within Papers
- TextEdit must be running.
- Keyboard Maestro is wonky when it comes to adding carriage returns—when typing the metadata I have to manually place carriage returns to separate information. I deliberately put a two second delay between each paste to give me time to press the return key.
- Do not interrupt the macro-interruption may result in data-overwrite or loss.
- The script gets the reference information from Papers—and prepends a “1. “ before the actual reference. This is both a bug and a feature—because of this, the new reference bubbles up to the top of the information (sorted by title name), but has to be manually removed.
Overall I have been incredibly impressed with Tinderbox and wished I had learned more about it years ago. My investment of time is already paying dividends. I’m currently using Tinderbox to draft a manuscript and a grant proposal. I will continue to blog about features as I learn more about the program. Enjoy.
Grantome - Website offers new insights into Successful NIH Funding
I recently came across a new (at least to me) website called Grantome. The site was developed by Cleveland, Ohio data scientists. Granthome’s mission is to use data to drive the discovery of new knowledge about scientific research grants. Grantome extracts data from various places and combines it into a single data source that offers insight (and, they claim, a competitive advantage) in procuring grant funding.Currently, only the U.S. National Institute of Health (NIH) is included. The NIH information is updated weekly. There are plans to expand Grantome to include the U.S. National Science Foundation (NSF), the U.S. Department of Energy, and federal grant organizations in Canada and Europe.I ran Grantome through its paces, conducting a search on the topic of the proposal I’m currently writing. The interface is simple, clean and intuitive. Granthome quickly spit out interesting information on my topic including: 1) the number of grants issued per year on my topic, 2) the authors of the successful grants on my topic, 3) the institution of the winning proposals, 4) the institute where the funding originated, as well as 5) the study sections that approved each of the successful grants.I will keep a close eye on Grantome and plan to use it with future funding proposals. I hope I’m able to meet up with this team during one of my frequent visits to Cleveland.Check Grantome out and let me know what you think!
Copied - a game-changing universal clipboard for all of your devices
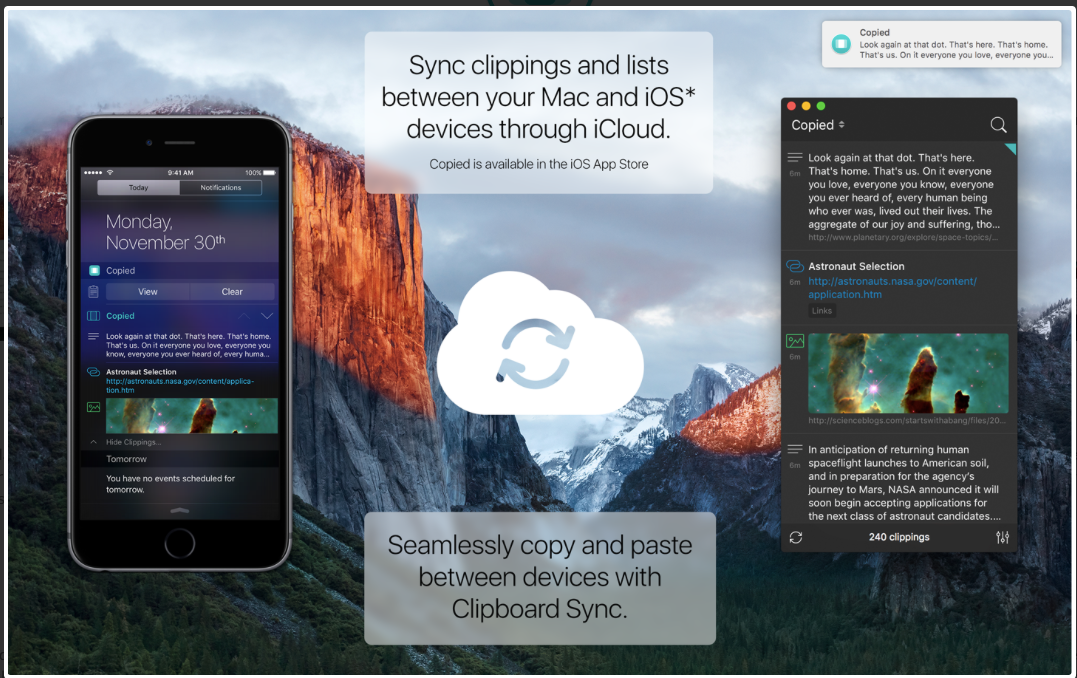
It is grant season and thus it's been quite some time since I've written an entry. Today I want to talk about the program I'm using quite extensively for writing and social media. The application is Copied. Copied is available both for Mac and iOS. Copied is a universal clipboard application that makes information available on all your devices (with an in-app upgrade). The ubiquitous availability of your clipboard, in my opinion, is priceless.
 Some of the ways I am using Copied:
Some of the ways I am using Copied:
- Capturing screen shots of my iOS devices for blog entries.
- transferring information from programs such as Drafts to my Mac (without having to use an intermediary program such as Evernote)
- Capturing information on my computer and transferring to my phone (e.g. addresses, screenshots, etc.)
- Capturing images from the web—Copied automatically captures the URL of the picture and appends it to the clipboard entry (saving me the time it used to take to copy this information manually).
- Quickly capturing the titles of references I wish to download after finishing reading a manuscript in Skim.
- Capturing the references from a manuscript to be added to each of my extracted annotations.
I find a new way to use Copied every week. Copied has features (such as automated scripting templates) that I have yet to explore. Even without these unexplored features, Copied is a powerful addition to my writing toolbox - well worth the price.I’d be interested in hearing how others are utilizing this phenomenal app in their daily work.
Highlights.app not ready for prime time
On recommendation of several people, I decided to try the annotation app, Highlights. Although I was intrigued with several of the features, after extensive use, I can’t recommend the app. The program still needs work before I could reliably use it in my writing workflow.I found two of Highlights features especially attractive:
- The ability to extract each highlight or comment as its own markdown file.
- The ability to underline references in the PDF and have those references automatically appended/linked to extracted notes.
I trialed Highlights for about a week. Ultimately, even with the intriguing features, The appnwas far too buggy for me to adopt.Here are some of the issues I faced:
- References would not reliably link to a note. I could find no rhyme or reason for this behavior. Sometimes the feature worked, sometimes it didn’t. No matter what I tried, I was unable to remedy this issue. My attempt at editing markdown files led to frustration—my edits were often erased.
- Even when the reference extraction worked, there is a bug that alters the markdown file, adding additional markdown to each reference. With many references, this bug makes each file unreadable.
- I found no way to configure the order, type, and appearance of the metadata.
- Extraction of figures from the manuscript were buggy and unreliable.
- Metadata was impossible to change. Initially, I set Up the app to automatically retrieve metadata. Unfortunately, several of the paPers the software Retrieved had erroneous metadata. Once imported, I found the metadata impossible to change. Since I add the title, author, And other metadata to every one of my extracted notes, this was The fatal flaw that caused me to end my trial.
Although I am intrigued by several of the features of the Highlights App, I will continue to use my tried and true method of note extraction using Skim. I plan keeping an eye peeled for these issues to be fixed within Highlights. With some improvements, I could see the app becoming my Mac PDF reader of choice.
Skim Split Screen Workaround
When reading PDFs on my Mac, I use Skim. Although I love the program, Skim has one annoying quirk. I cannot select (or highlight) text in a split screen. This makes it difficult to highlight or download references in real-time.I found a workaround that is fast and efficient. After opening a PDF in Skim, I’ll select “Print” from the File Menu and then, from the bottom left drop down menu, I’ll select “Open PDF in Preview.” This opens a second editable version of the manuscript side-by-side with the original.Let me know how this works for you.
Scrivener iOS coming on July 20!
I have been quite impressed with the Scriver iOS Beta--it's capabilities far exceeded my expectations both on my iPhone and iPad. It has already simplified my Writing Workflow. I'm not alone in my exuberance. Check out this glowing review. The wait for The official release is almost over....the official date Is July 20 at a price of $19.99. There will be a simultaneous release of a new version of Scrivener for Mac.
New NIH Grant Requirements - Critical Evaluation of Existing Literature
For those of you that write NIH grants for a living, you are well aware of the changes required for new grant applications in 2016. In an effort to improve rigor and transparency as well as to increase reproducibility, The NIH now requires the grants to be written in a whole new way. A major part of these changes has to do with critical evaluation of existing literature.In light of these changes I have been formally appending my manuscripts a new way. In previous entries I’ve written how I take notes while reading, then extract these highlights and notes to their own individual files. Now, as I'm reading, I make and effort to record perceived strengths weaknesses of each study appending my comments with the text “StrengthX” or “WeaknessX.” I then extract each comment as its own text file. When writing grants or manuscripts, using Devonthink, I’m able to find similar notes to the one I’m reading. By appending StrengthX or WeaknessX, I’m able to single out my own comments instead of a seeing every instance of each word.In a future entry, I’ll talk more about the ways I’ve updated finding extracted information using Devonthink (and Tinderbox). A good portion of my writing workflow from 2015 has changed. I will write an updated writing workflow after the official release of Scrivener iOS.I'd be interested to hear how other academics are dealing with the changes at the NIH. Please leave a note in the comments below.
Using Skitch and Papers to Capture Figures and Tables
Few would argue that the most important point of a scholarly manuscript is made in its figures and tables. I am going to share with you how I capture figures while reading scholarly information on my Mac. This workflow uses:SkitchPapersInstall Skitch and make sure, in Skitch Preferences, to enable the “keep Skitch Helper running in background when I quit,” and “Start Skitch Helper when I log in to my computer.” As I’m reading scholarly literature and come across a table or figure I want to save I do the following. I make the figure as big as possible on my screen. Then, from the Skitch menu in my menubar, I select the Crosshair Snapshot. I then select the figure (and sometimes the caption) trying to balance the white space surrounding the figure.Next, I go to Papers, select the reference in my Papers Library, and then from the Edit Menu:Copy As:Reference.I return to Skitch and double-click at the bottom of the figure then paste the reference text. I then balance the text. The height of the Skitch figure will expand to accomodate the new text.
As I’m reading scholarly literature and come across a table or figure I want to save I do the following. I make the figure as big as possible on my screen. Then, from the Skitch menu in my menubar, I select the Crosshair Snapshot. I then select the figure (and sometimes the caption) trying to balance the white space surrounding the figure.Next, I go to Papers, select the reference in my Papers Library, and then from the Edit Menu:Copy As:Reference.I return to Skitch and double-click at the bottom of the figure then paste the reference text. I then balance the text. The height of the Skitch figure will expand to accomodate the new text. When I want to refer to or use the table or figure I view it directly in Skitch or find it in Evernote. Using this method, I can also search for words in the reference (e.g. the author’s name or the title of the manuscript) and sometimes even the words in the figure itself.If I want to use the figure in a presentation or to send it to a colleague or trainee I can export the figure from the Skitch File Menu.Using this method I’ve captured hundreds of figures. I hope this workflow helps you too.
When I want to refer to or use the table or figure I view it directly in Skitch or find it in Evernote. Using this method, I can also search for words in the reference (e.g. the author’s name or the title of the manuscript) and sometimes even the words in the figure itself.If I want to use the figure in a presentation or to send it to a colleague or trainee I can export the figure from the Skitch File Menu.Using this method I’ve captured hundreds of figures. I hope this workflow helps you too.
Lifehacker Review of Ulysses.app
Thorin Klosowski wrote a great review of Ulysses App on Lifehacker. Check it out.
MacWorld Review - Ulysses for iPhone
Macworld has a glowing review for Ulysses for iPhone in the May 2016 issue. I agree with the review, the app dwarfs all other writing programs on iOS. Check out the article and check out the app here.
Scrivener iOS: From Alpha to Beta
It looks like our long wait may be over. A post on the Literature and Latte blog this week said the iOS version of Scrivener will move from in-house Alpha testing to wider spread Beta testing. From the article, looks like they will choose a small number of primary Beta testers to kick the tires....once the egregious bugs have been found they will move to more wide-spread testing. Regardless, I can hardly wait. Scrivener iOS is going to simplify my writing workflow quite significantly.
Importing Microsoft Word files into Ulysses
I subscribe to the newsletter from Soulmen, the makers of my favorite text / markdown writing app, Ulysses. From the newsletter, I learned it is now possible to import Microsoft Word .docx documents. The article said it was possible from any device, but I could only do it using the instructions for iPhone (not on my Mac).In order to import a Word file, it must be in a folder Ulysses can access. Within Ulysses iOS, choose the group where you’d like your imported document to live. Then at the bottom right of screen, choose ‘import’ and select your file. The Word document is converted to MarkdownXL with your formatting intact.Happy writing!